The processor for temporarily storing of data and program instructions uses primary storage. Primary storage contains registers, cache and memory. Secondary storage is a permanent storage facility that includes things like floppy disks, hard drives, CDs, etc. In some devices they treat primary storage as if it was secondary storage, with leaving power to the primary storage. When primary storage is getting no power then all its contents are lost.
Most of the time a processor is only able to execute code from with in primary storage. All the data processing is also done in the primary storage areas. This means that data/code has to be copied to the primary storage before it can be used. The access to secondary storage is usually done via accessing special memory locations in the memory map and/or via special registers.
There are two different kinds of Registers. The first type provides a temporary storage mechanism for the CPU while it is executing OpCodes. This type of storage is the fastest out of all the primary storage devices, but this is also the smallest amount of memory in the system. Examples of this register type include general-purpose registers, floating point registers, program counter, etc.
The other type of registers is used for special operations. These registers commonly provide the only way to access many of the systems special features. Examples of these kinds of features include DMA (Direct Memory Access) transfers, setting up the screen, querying the status of different external devices. These types of registers are sometimes called control registers, or ports. Accessing these registers vary greatly between different systems, in general they are accessed through special OpCodes and/or through special memory locations in the memory map.
In emulating the first type of registers an array of variables is created to simulate the
target systems internal registers. The amount of register that have to be emulated is system
dependent, in a MIPS processor you have 32 General-purpose registers, with the first register
being hard wired to always contain the value of 0. On an x86 processor you have 8 general
registers. If you were emulating a MIPS based processor, where the general purpose registers
are 32bits then the declaration for the registers would look like this:
| unsigned int GPR[32]; |
If the system you are emulating on contains more registers than the target system, then you can take advantage of this by permanently allocating the general-purpose registers to a system register than a variable. The main reason why you would you would want to do this is that when the computer has to do some type of modify the variable or wish to use the value in the variable it has to move this value to a register and if modified written back to the variable. So the less you move the variables to a register and back again, the faster the emulator will run.
Cache is faster then the main memory but slower than the registers. You will find more memory available in cache compared to registers but dramatically less compared to main memory. Most systems will have cache memory that is in general transparent to the program. The cache is used as a buffer for code and data that is commonly being used. The cache might make no difference to how the program works, but it does make a difference when you are trying to get the program to run faster. Understanding the cache can help programmers to better optimise their programs.
The emulation of cache is not really needed as it is a means of speeding up the hardware not giving any functionality. The nice bonus of emulating the cache is that you are able to see what is in the cache, which is not possible in the original hardware. This could help some programmers to work out if they are having problems with the cache and are able to trace the error easier. In some systems the cache can have some side effects so it is important to understand how the cache works on the target system, just in case there are side effects you need to implement.
This is the largest and slowest part of primary storage devices, which is still a lot faster than any secondary storage devices. The main memory is used as a caching system for secondary storage devices. The memory is also used for temporary storage. In some systems pieces of hardware may have their own separate memory from the main memory for it's own specific task.
Memory is a finite resource and in a system that can run multiple applications at the one time, the memory can be used up very quickly. The method that is used to get around this is where a portion of a secondary device is allocated for use as memory. This is called virtual memory. As the secondary storage section is going to be a lot slower then the rest of the main memory, you will general find that things are very rarely accessed in the memory get moved to the second storage partition. This gives the appearance of a lot more memory than the system really has. The only down side of this method is that it can dramatically slow the computer down when you have to change things between the normal memory and the virtual memory.
What does this all mean to emulation? Well in emulating the main memory we just set up a single array of bytes, which is the same size of the RAM in the system. This is what causes emulators to chew up a lot of the system resources. So if the emulator is aimed at a computer with few resources you should be aware of how the system manages the memory, so the emulator is wasting as little resource that it can afford to. Virtual Memory can mean the emulator can just assume that the platform always has enough memory.
When you are moving data to and from the memory, this may not always be the main memory
that you are directly accessing. A memory map will show you how the memory addressing system
is layered out. This allows you to understand the effect that is generated from writing to
these different memory areas. Here are some of the common sections that the memory map is
broken in to:
* Main Memory - This is just a bank of memory as described above.
* Mirrored Memory - This is where you have multiple locations to read/write to a single
section of memory. When one section of this memory is modified, you can see that change in all
the other mirrored memory sections as well.
* Protected Memory - On some systems you may be able to manual protect the memory. For
other parts of the memory map this may always be permanently protected. The memory can be
protected so that when you read or write to this address it is either ignored, or generates an
error. On some systems the way it reports to the program that it has caused an error is to
generate a exception specific to writing to protected memory.
* Special Registers - This section of the memory map provides access to the system special
registers as described above.
* Memory Banks - On some system, the main memory cannot be accessed in a pure linear
manner. What you have is bank of memory sections with an index stating which memory section is
being accessed. This means that you have multiple pages mapped to the same area with in the
memory map. And to gain access to the other pages you have to swap the current foreground memory
page with one in the background.
In an operating system where you have multiple applications running simultaneously, one of the feature's that is highly useful is to stop other applications modifying the memory of another application. If an application can gain direct access to all memory then there is no way to be able to stop this. This is where the TLB comes in handy to an operating system. The TLB provides a mechanism where you access memory through a virtual address instead of accessing the memory directly. Rules are set up directing what memory can be accessed, thus allowing the system to stop applications having any chance to modify another applications memory space. The method that explains how the TLB entries are used in translating the address is usually well explained in the system manual, as this is system dependent. In a lot of cases there are parts of the virtual memory that do have TLB entries set up for them. If the application tries to access these undefined memory areas then this will commonly generate some type of exception giving control back to the operating system so that it can process how to handle this and set up accordingly for the application. In some operating system you might find the TLB entries as part of the context switch for each process.
When it comes to emulating the TLB, the emulator could just go through every TLB entry for any store and load operation and see if a match could be found. This method will work well and accurately, just very slow as well. The main problem with emulating the TLB is that you will find that it can dramatically slow down the speed of the emulator. The better you understand how the TLB is implemented in the target system the better you can create algorithms to get around this. Some of the ways you can get around this is by using look up tables or using the internal TLB of the computer you are running the emulator on.
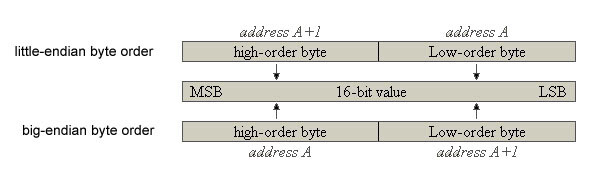
The order with in which bytes are stored with in memory when data is stored is referred to as endians. There are basically two styles little-endian and big-endian. Say we have a 16-bit value (two bytes) and the least significant byte in this value is stored at the first byte of this address then this is known as little-endian byte order. When the most significant byte is stored at the starting address then this is known as big-endian (as seen below). Unfortunately there is no standard for which method should be used, so a system could use either method. Some systems are even able to use either method.
Endians is something you may or may not have to worry about in emulation, if both systems use the same method then this is just something interesting. On the other hand if the two systems are using different endian formats then you will have to covert the memory to generate the correct results. You might be treating the memory as permanently swapped and when you load something to the emulator you flip the memory then. Or you may find only when you are loading to and from the registers you flip the memory. There might even be some happy medium between the two.
Within a system where you have hardware performing tasks in parrel to the CPU, then the program needs to be able to know when different tasks have been finished. Some programs may spin reading the status of a device to monitor its state. The better method is where the hardware tells the program through an interrupt that way the program does not have to waste CPU cycles to spin on the status. Here are some of the common things that the hardware does that can help a program to integrate with the system. The system may have other capabilities, which you should be able to find in the CPU manual for the system.
A timer mechanism provides the ability to synchronise a program to the real world. If the program is being run on systems where the speed of the CPU varies then you will find that program needs to synchronise with the timer so that the program will run at the same speed across all CPU that is designed for. If this was not used with in a game then you will find with the every improving hardware that the game would become unplayable, as it would be to fast. Applications would not need to worry about this. When the timer can schedule interrupts to occur at specific times then this can allow operating systems to do pre-emptive multi threading scheduling.
Emulating the timer accurately is probably the hardest thing to do with in an emulator if not impossible. The timer mechanism is usually based off clock cycles not the time. If we added up how many cycles each operation should take and added up all those values, we would still not have the correct time that it took to do these operations. This is because it is hard to determining how some of the actions will effect the time taken in performing the OpCode for example pipeline stalls, cache misses, etc. Other than we cannot get this accurate, either can the application, so just adding up these times is not correct but it is generally accurate enough to get away with the appearance that it is correct.
With emulating the timer the most common method is to have a variable that represents the timer then we just minus/add the number of cycles that each operation was meant to take. These values may vary depending on the parameters to the OpCode.
These are updated or performed in the system at a regular interval with in the system without
the program having to constantly to set them up to do there task. Some cyclic tasks are performed
at constant intervals where others may vary when they occur. Some of the common cyclic tasks
include:
* Screen refreshing
* Input device status
* Other external device status, like sound.
As these tasks happen at different times we should be checking them after each OpCode, but doing this dramatically affects the performance of the emulator. To get around this the emulator should check at the max interval of cycles between these different events. It is also best to bunch the updating together as much as possible. One of the best ways of handling this is to calculate how often these different tasks occur and then find the greatest common divisor of these numbers. You can then use this number as a timer and count it down when it is less than zero add the count value to it again, and update the system. This way you are still updating the system with no visible side effect other than a speed increase, this may not be totally accurate but the difference should not be noticeable.
Interrupts and exceptions provide a way for the hardware to communicate with the software. Interrupts are generally a type of exception telling when a specific state in the system has changed, or some event has occurred. One of the common types of interrupts is when the screen has finished refreshing and it is safe for a small period of time to draw a new screen for the next refresh.
Exceptions provide a mechanism to inform the software that something it has tried to do has failed, this can include executing unknown instructions, a TLB miss, divide by 0, etc. Processing an exception varies from system to system so you will have to see exactly how the target system processes an exception. The general method that exceptions take in processing is that there is a special location with in the memory map that the program counter will jump to. When the program counter jumps to this location the information about the state of execution is preserved so the system is able to return and continue after processing the exception.
When you emulate exceptions/interrupt all you have to do is make sure you set all the specific registers according to what is meant to be preserved. What exactly should occur things should be documented in the systems documentation. You just have to make sure that the emulator has exceptions/interrupts occurring when they are meant to be.
High/low level emulation is a term that has become more heavily used, but does not seem to be well understood from non-emulator writers. A low-level emulator is where you are just emulating the hardware and what this document describes. You will find that most emulators that are currently available are low-level emulators. Other than low-level emulation has been around a long time it has only been given this name recently to show a contrast to a high level emulation.
High-level emulation on the other hand is a hybrid of hardware emulation and software simulation. This type of emulation is useful when you have programs you are emulating that share common static code. This type of emulation is mostly useful in emulating an operating system, where the operating systems calls are simulate and the rest of the program being emulated.
High-level emulation is faster in seeing results from an emulator with a specific program, it is also easier to get it to run faster as the simulated code will be optimised for the target system and the methods are not dependant on how the other system worked internally. Another big advantage of High-level emulation is where multiple programs use the same static code to access and control specialised chips, when this happens you are able to emulate the function calls with out having to understand how that chips works. You just need to understand what the function is meant to do. Another advantage to high-level emulation is that you do not need all the binaries need to make the select application run. This means that say you were emulating an operating system and you high levelled all the operating system calls then you could run an application for that operating system with out running a copy of the operating system. This means you could emulate a target system with out the user having to buy the operated system it was designed for.
This makes high-level emulation sound very appealing and it is in specific situations. The problem with high-level emulation is that if there is no common code between applications then high level emulation is impossible. Also to get a specific application to run it is generally quicker if you use high level emulation, but when you want to get a lot of different applications to run then you will start to notice that high level emulation is a lot slower to produce. If you had a 1000 different system call you would find in low level emulation that after you got the first couple going then there would be less and less to do in future calls. But in high level emulation, you would have to do each function uniquely and code you did for one function would not carry across to the other system calls. So you find that low level takes longer to get results, but once you start getting results it is a lot quicker getting other things to work.